Reproducing Network Research on HTTP over UDP: HTTP/1.1 vs HTTP/2 vs soon-HTTP/3 (QUIC)
April 29, 2024 07:58
This experiment aims to replicate a section from the study ‘HTTP over UDP: an Experimental Investigation of QUIC,’ comparing QUIC with SPDY (HTTP/2) in terms of the percentage improvement in page load time over HTTP/1.1. The analysis focuses on three categories of pages: small, medium, and large. The smallest page weighs 305kB and includes 18 x 2.6kB and 3 x 86.5kB JPEG images, with larger pages doubling in size and featuring more images. Various scenarios, including packet loss, network protocol, and bandwidth, are considered as factors.
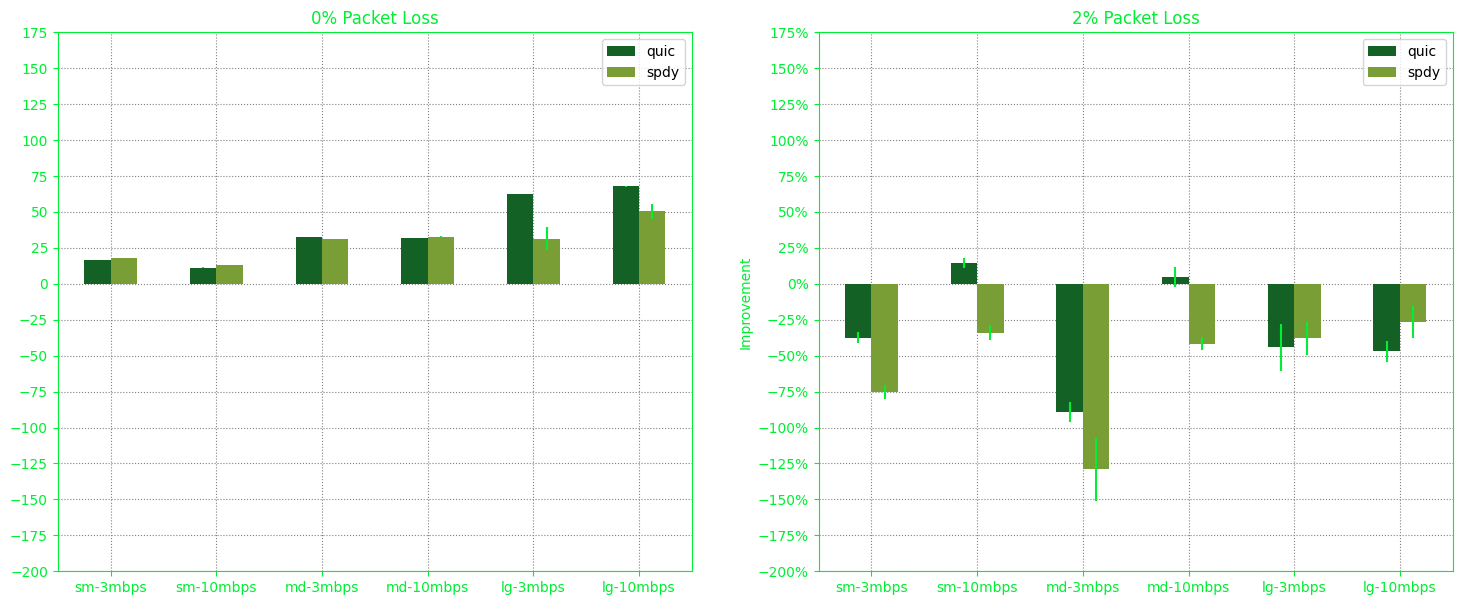
This is our result:
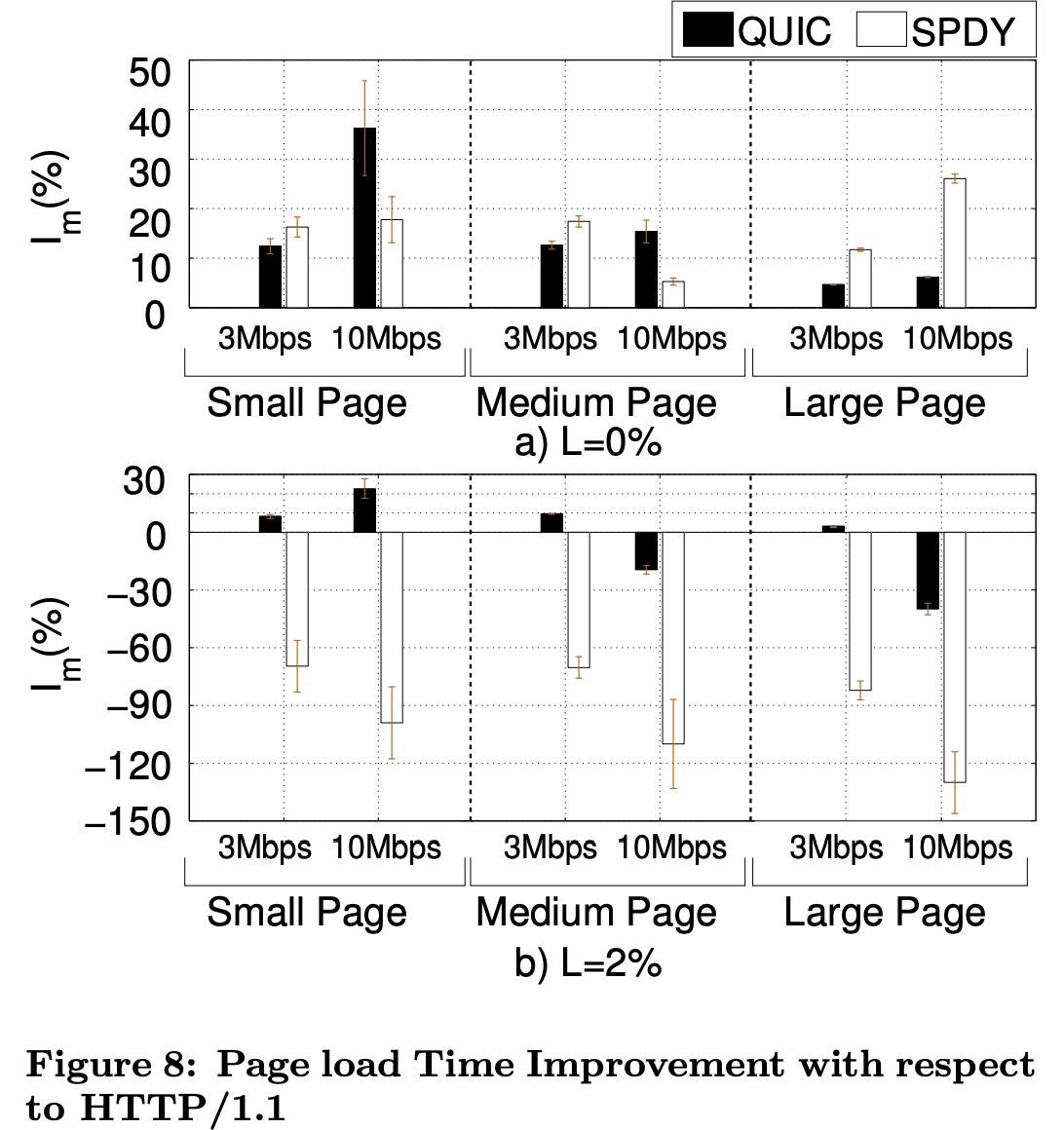
Below is from the research paper:
In our experiment, sm-3mbps means the small page on 3 megabytes/sec bandwidth. And so, md and lg means medium and large respectively. In the research paper they have clearer naming.
Regardless, our experiment agrees that, on average, QUIC performed better, if not on par with SPDY when contrasted with HTTP/1.1. Our key observation is that under stable conditions with 0% packet loss, both HTTP/2 and QUIC consistently outperform HTTP/1.1.
However, it’s worth noting that we used a different set of technology than the original paper. While they employed Netsharper, we utilized iptable and Chrome’s own mechanisms as Netsharper has been close-sourced. In a way, we believe this is great as it can mean our result is a variation, if not a refresher, to the original research that was published almost a decade ago, specifically in 2015.
The main challenge in reproducing the original paper stems from, in our opinion, its inadequate description of the testbed environment. For instance, the paper fails to mention the number of times data was collected for a page. In our approach, we conduct 9 runs for each page to mitigate variability in performance metric collection. When we ran the tests only twice, we observed an anomalous result: loading a small page was faster with 2% induced packet loss. That makes almost no sense.
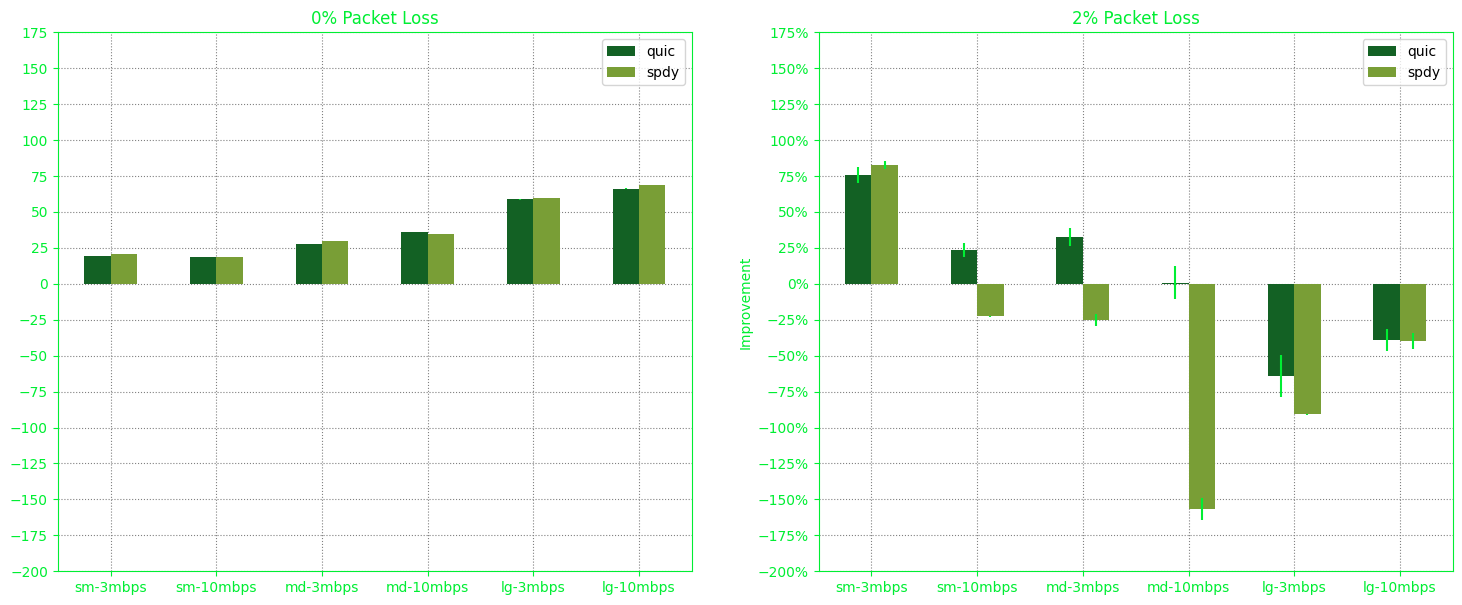
Equally important, we’re not sure if caching was allowed, if images were numerous or identical, if the client and server were geographically close, or if page load time was measured since browser opening or since DOM rendering, among other things.
In our setup:
- To our knowledge, we don’t employ any caching. Our server lacks caching capability, and our client utilizes separate user data folders to prevent browser caching further down the line.
- We use a modest E2-micro server instance hosted in the ‘us-west1-b’ region of the Google Cloud Engine.
- Our client nodes are located in Surabaya, Indonesia. One is a 2021 Apple M1 MacBook Pro machine running macOS Sonoma with 32GB of memory, another is a Microsoft Surface Laptop 4 running Ubuntu Linux with 8GB of memory.
- We used Google Chrome.
- We don’t inhibit bandwidth or packet loss at the server side.
- We measure page load time from the moment the browser opens our page until it completes rendering. To warm up the browser, we initially load Google before hitting the server. However, when testing for QUIC, pages were loaded twice, and measurements were taken only on the second load. This approach was adopted because browsers typically use the HTTP/2 protocol for the initial hit, switching to QUIC for subsequent hits if the web server supports it.
- We executed 9 runs for each page, for each protocol, for each bandwidth setting, and for each induced packet loss.
Our server, a simple Go app, listens on port 3000 for HTTP/1.1 with TLS and port 8080 for HTTP/2 or QUIC (also with TLS for both). We avoid Apache, as we want a smaller memory footprint. In hindsight, we should probably be using Rust to avoid stop-the-world garbage collection.
When the client and server are on the same machine, our results varied significantly between different test runs, largely due to operating system scheduling. This scheduling, necessary for managing multiple applications, can impact performance and the accuracy of gathered data. Therefore, it’s advisable not to run both on the same machine. However, even with separate machines, uncontrollable factors on the Internet, like changing nodes and shortest path variations, can still lead to result discrepancies. The most controlled experiments occur when we own the network, but such an experiment must be costly.
We also compared our experiment with that of Kyle O’Connor who also attempted to reproduce the research. Their attempt yields the following result:
I’d like to showcase the variations in results, as it provides an intriguing insight into how different setups can produce varying outputs:
-
We decided to introduce longer sleep intervals to minimize the likelihood of content caching by intermediary servers, such as those controlled by ISPs. This adjustment led to the production of the ‘5BA98058’ result:
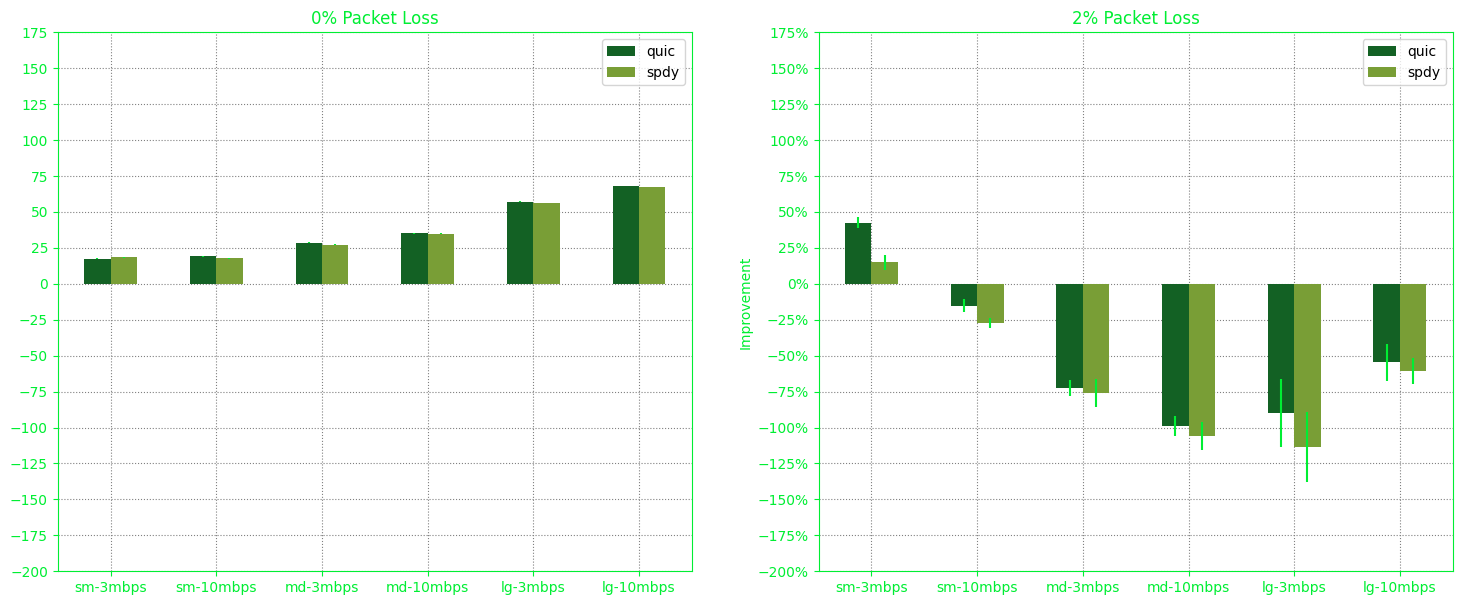
-
Interestingly, with exactly the same configuration with that of “5BA98058”, a rerun yields “1B7B97A” which highlights network flakiness:
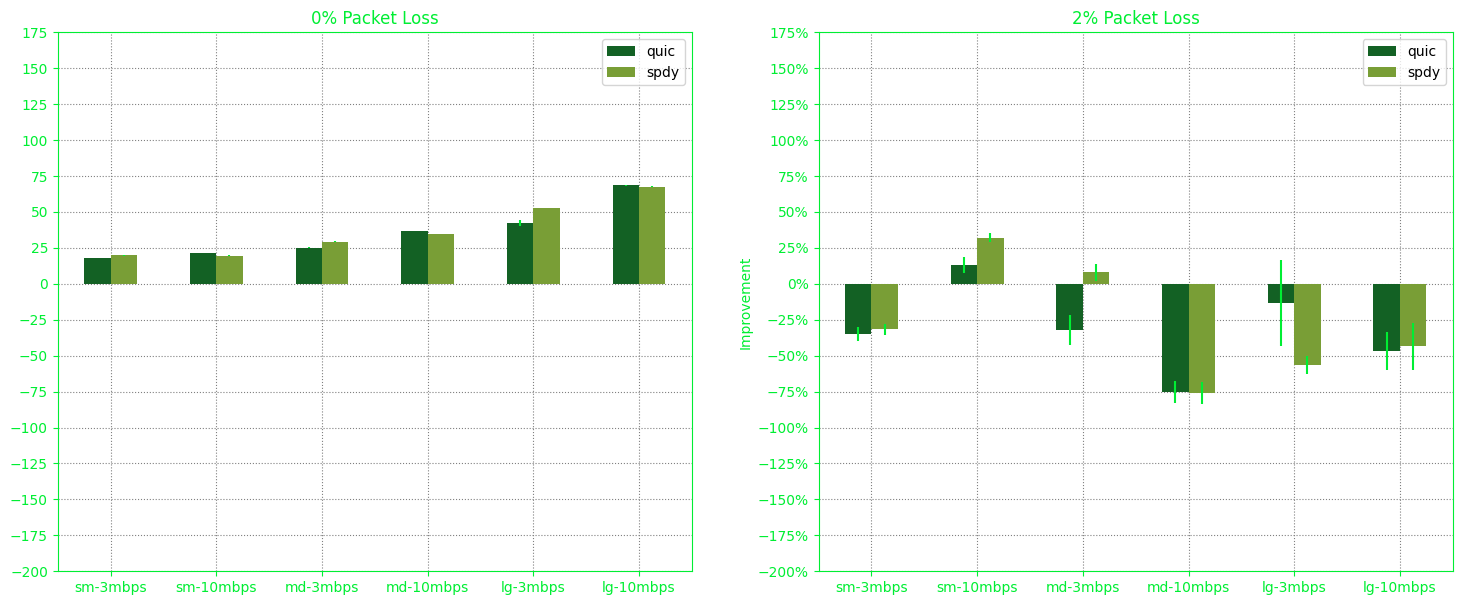
This variability can be attributed to the random nature of packet loss. Sometimes, it may affect each page equally badly, while other times, it might significantly impact only one page. However, when there’s no packet loss, the results tend to be more consistent.
-
Now, let’s compare ‘5BA98058’ and ‘1B7B97A’ on macOS to those from our Microsoft Surface Ubuntu machine, which yielded ‘6418ED69’:
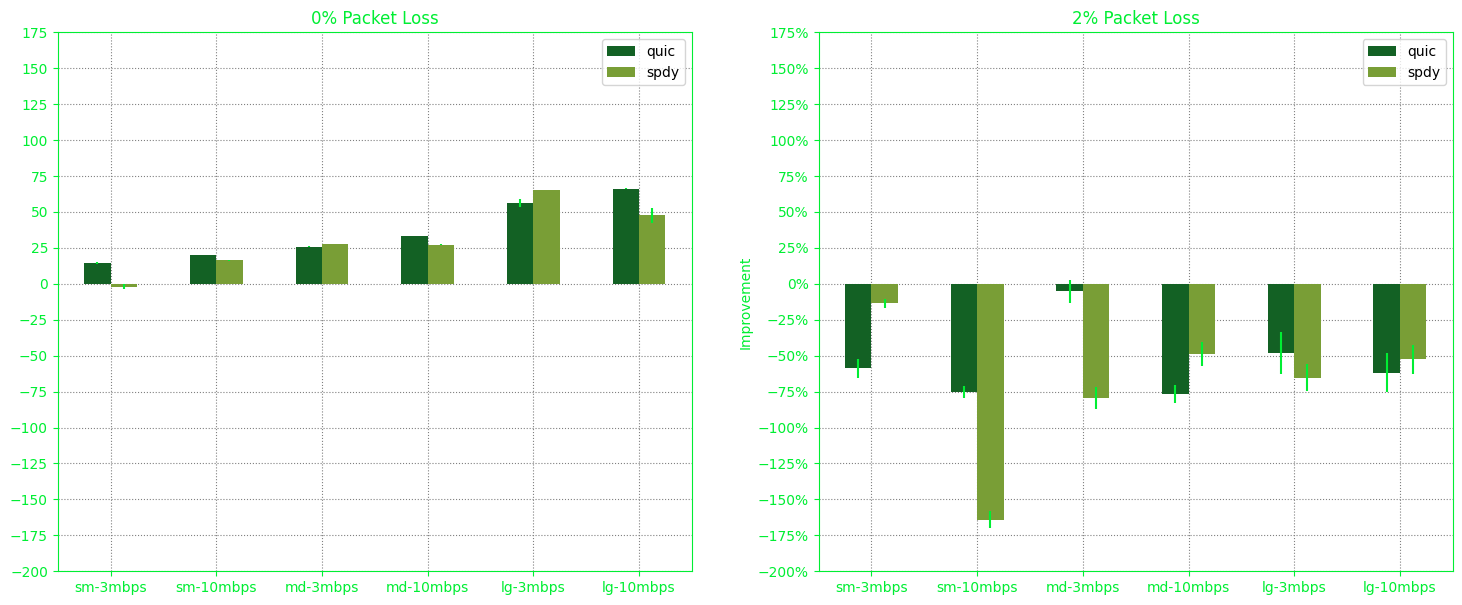
The key observation remains consistent: under stable conditions with 0% packet loss, HTTP/2 and QUIC consistently outperform HTTP/1.1.
-
The ‘22D984D4’ experiment placed both the client and the server on the same machine, yielding a result that defies common sense.
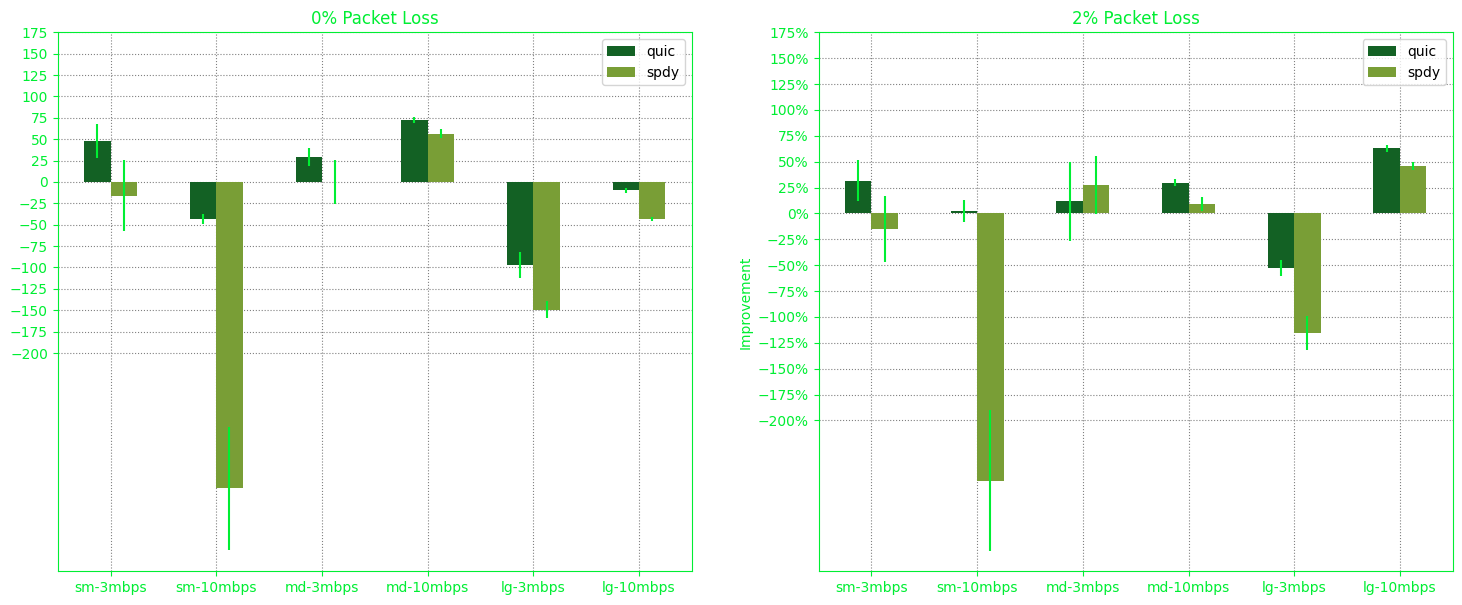
At the end, it was really fun doing this experiment.
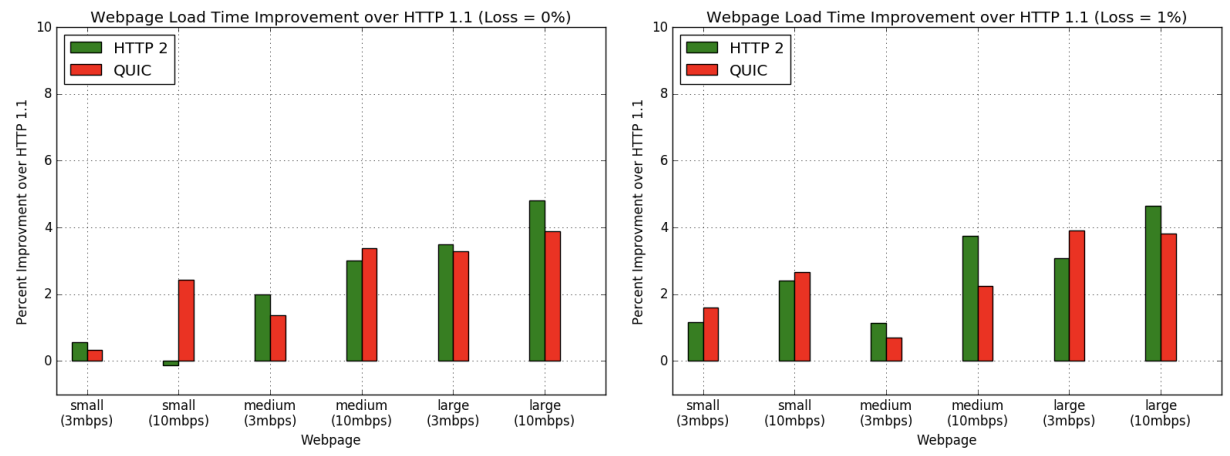
Another:
- The original HTTP over UDP: an Experimental Investigation of QUIC paper by Gaetano Carlucci, Luca De Cicco, Saverio Mascolo.
- Research by Kyle O’Connor: https://www3.cs.stonybrook.edu/~arunab/course/2017-1.pdf
- Benchmarking HTTP/3 performance